Demystifying The LLM Engine: Your 7-Step Guide To How AI Thinks

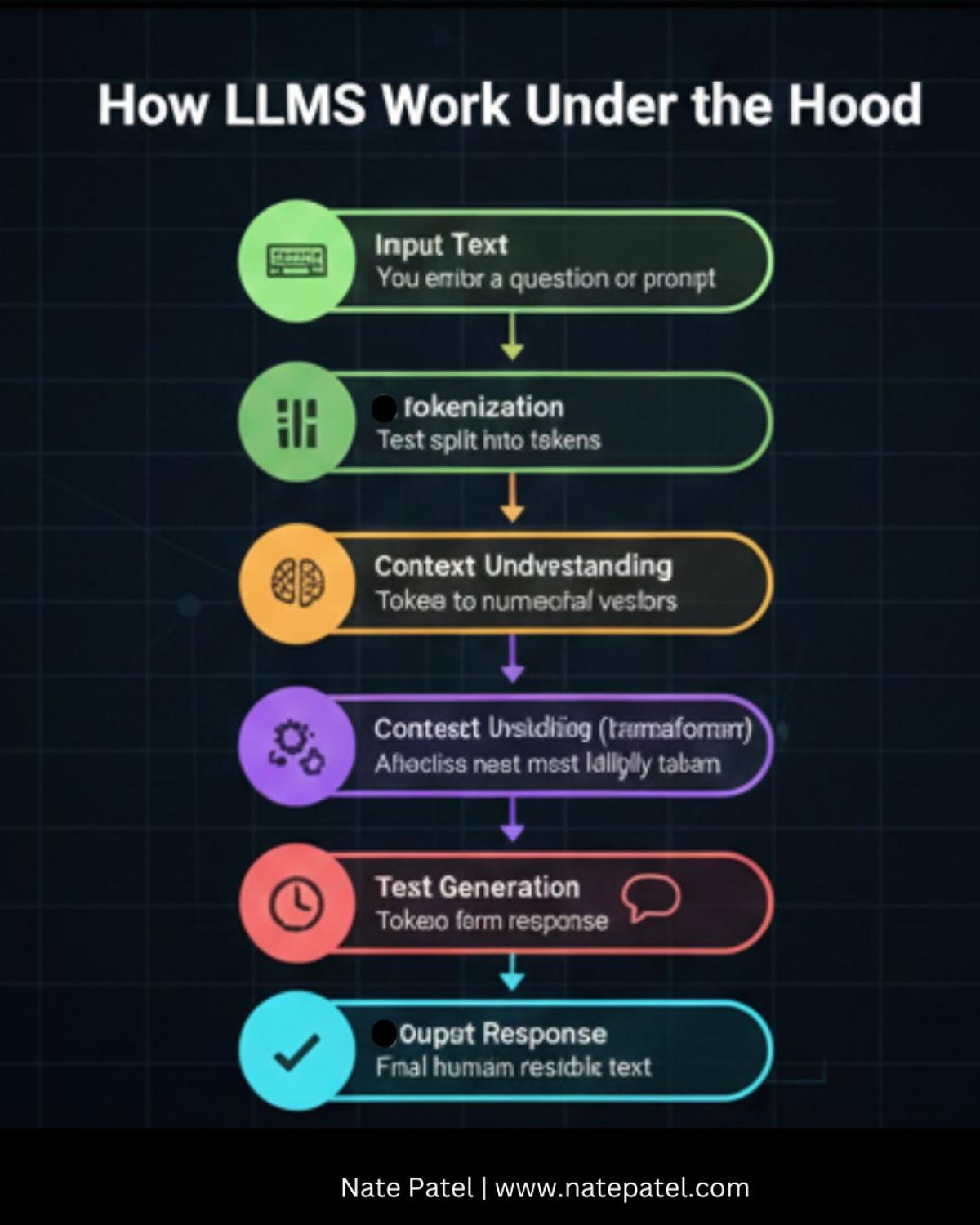
It visually explains the journey from a simple text input to the final generated output:
- Input Text: The initial question or prompt you provide.
- Tokenization: Breaking the text into fundamental units (tokens).
- Embedding: Converting these tokens into numerical vectors that capture meaning and context.
- Context Understanding (Transformer): Using sophisticated attention mechanisms to map relationships between all tokens.
- Prediction: The core function where the LLM calculates and predicts the next most statistically likely token.
- Text Generation: Iteratively generating tokens, building the complete response sequence.
- Output Response: Delivering the final, coherent answer in human-readable form.
Learn the sequential steps behind the incredible text generation capabilities of AI models like GPT and others! For more insights into the mechanics and future of cutting-edge AI technology, visit https://www.natepatel.com/.
0
Save